|
I am a Ph.D. Student at Cornell Computer Systems Lab and an SRC Jump 2.0 research scholar. My advisor is Prof. Mohammad Alian. Email / CV / Google Scholar / LinkedIn / Github |

|
|
My current research has focused on runtime development and data movement optimizations for accelerated systems. Previously, my work focused on near-memory acceleration of network protocols and (de)compression for memory expansion. |
|
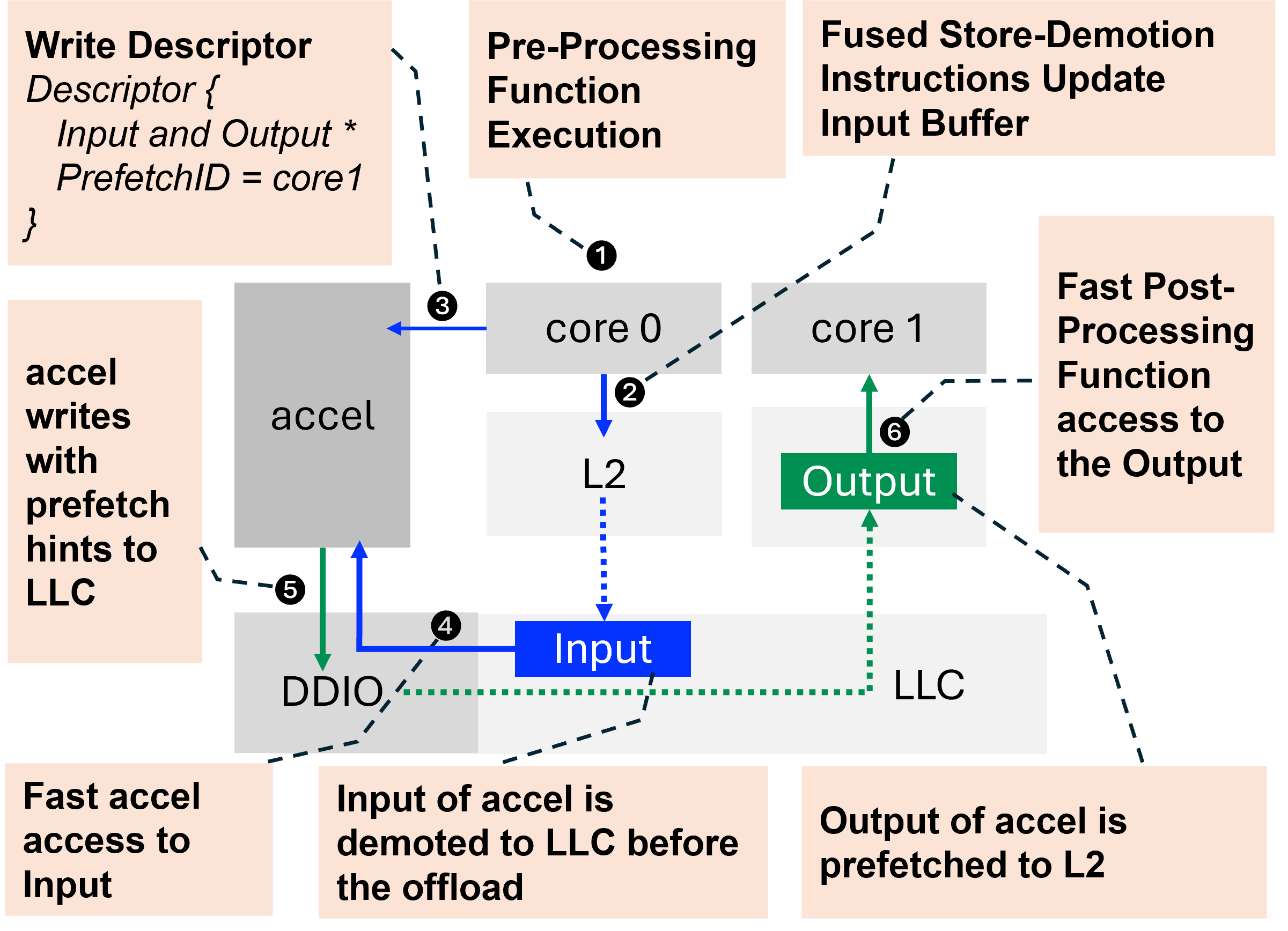
Neel Patel, Ren Wang, Mohammad Alian ACM Transactions on Architecture and Code Optimization (TACO), 2025 Paper | Code A hardware architecture and runtime system that evades the danger of end-to-end slowdowns when using hardware acceleration by leveraging a low-overhead interface between general-purpose cores and on-chip accelerators, fine-grained context switching, accelerator-initiated preemption, and seamless data motion between general-purpose cores and accelerators. |
|
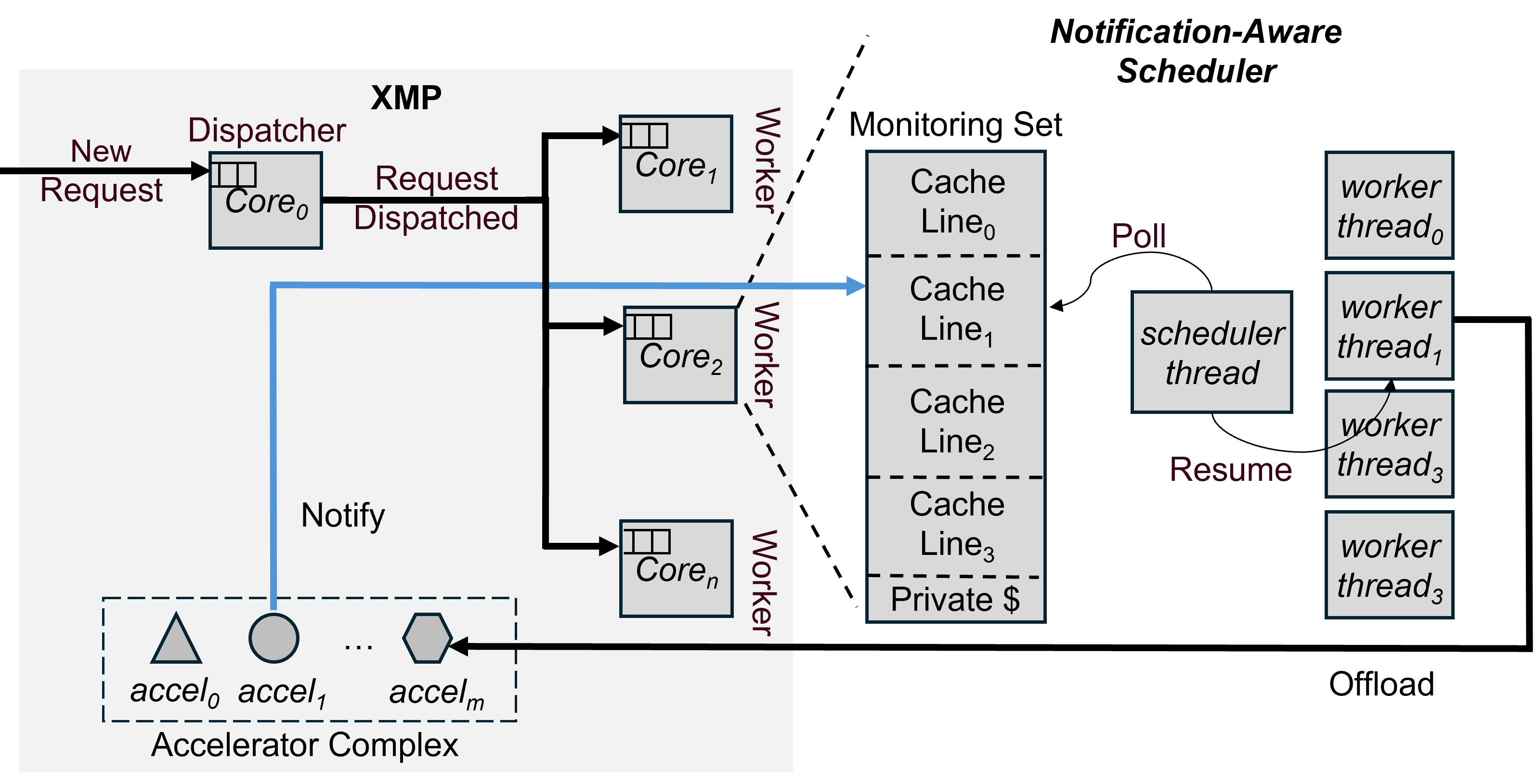
Neel Patel, Mohammad Alian USENIX Annual Technical Conference (ATC), 2025 Paper | Video | Code A runtime for accelerated CMPs, designed to scale to many-core, many-accelerator CPUs, which achieves up to 3.2× higher throughput-under-SLO and never introduces slowdowns from using on-chip accelerators. |
|
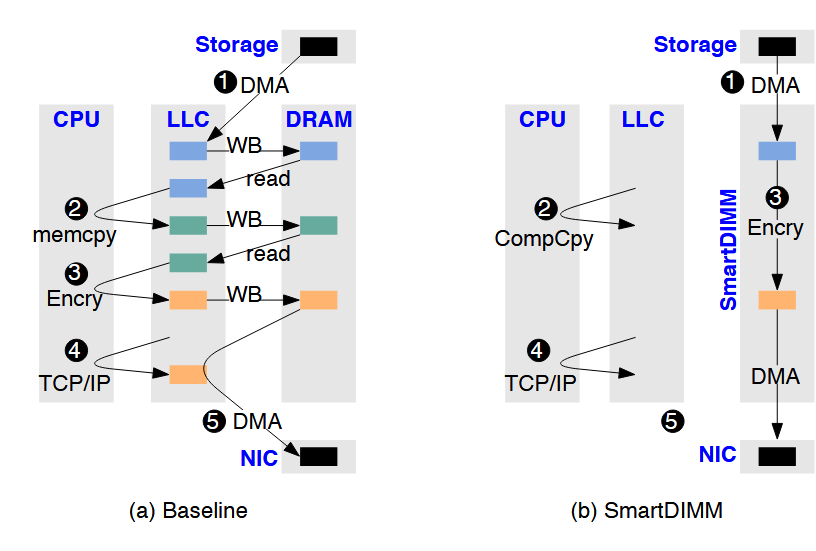
Neel Patel, Amin Mamandipoor, Mohammad Nouri, Mohammad Alian International Symposium on High-Performance Computer Architecture (HPCA), 2024 Paper | Code A near-memory system architecture (prototyped on Samsumg's AxDIMM), which accelerates datacenter upper layer network protocols--i.e. (de/en)cryption and (de)compression. In comparison to a server executing (de/en)cryption and (de)compression on the CPU, SmartDIMM achieves 21.0% to 10.28× higher requests per second and 36.3% to 88.9% lower memory bandwidth utilization. |
|
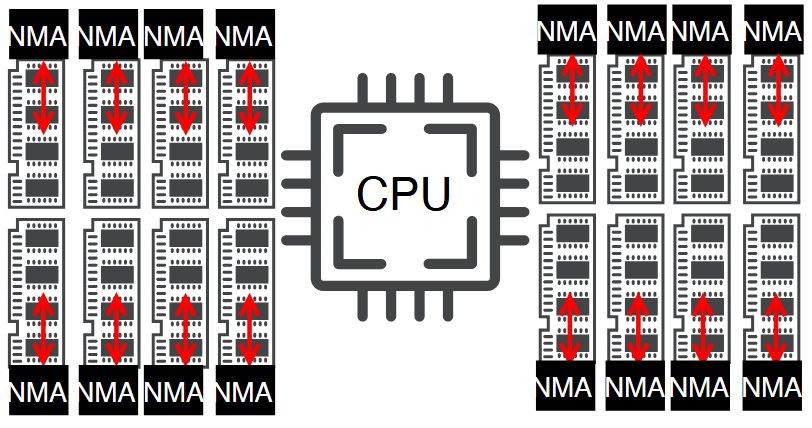
Neel Patel, Amin Mamandipoor, Derrick Quinn, Mohammad Alian ACM International Symposium on Microarchitecture (MICRO), 2023 Paper | Code We develop a near-memory accelerated far memory tier, which expands memory capacity through application-transparent (de)compression. FPGA implementation, simulation, and analytical modeling shows 5-27% memory and cache utilization reduction for a far memory tiers with a 1TB capacity. |
|
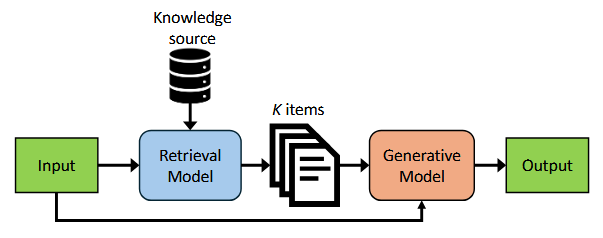
Derrick Quinn, Mohammad Nouri, Neel Patel, John Salihu, Alireza Salemi, Sukhan Lee, Hamed Zamani, Mohammad Alian International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2025 Paper Intelligent Knowledge Store (IKS), a type-2 CXL device that implements a scale-out near-memory acceleration architecture with a novel cache-coherent interface between the host CPU and near-memory accelerators. IKS offers 13.4–27.9× faster exact nearest neighbor search over a 512GB vector database compared with executing the search on Intel Sapphire Rapids CPUs. |
|
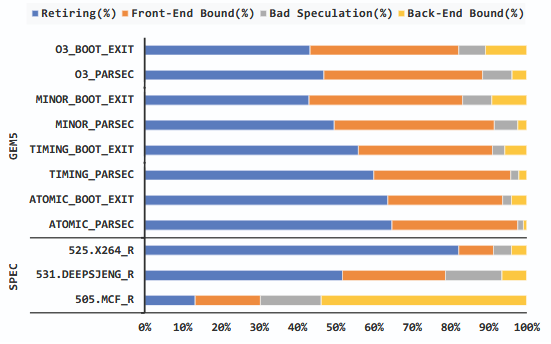
Johnson Umeike, Neel Patel, Alex Manley, Amin Mamandipoor, Heechul Yun, Mohammad Alian International Conference on Architectural Support for Programming Languages and Operating Systems (ISPASS), 2023 Paper A detailed architectural analysis of the gem5 source code on different server platforms. |
|
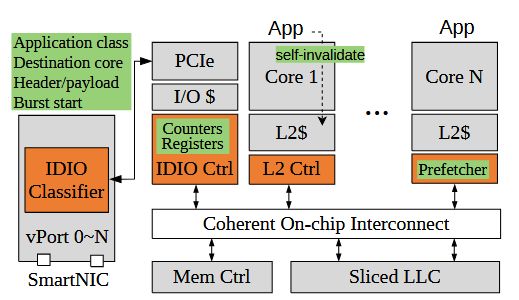
Mohammad Alian, Siddharth Agarwal, Jongmin Shin, Neel Patel, Yifan Yuan, Daehoon Kim, Ren Wang, Nam Sung Kim International Symposium on Microarchitectur (MICRO), 2022 Paper An intelligent direct I/O (IDIO) technology that extends DDIO to the MLC. Reduces data movement (up to 84% MLC and LLC writeback reduction), provides LLC isolation (up to 22% performance improvement), and improves tail latency (up to 38% reduction in 99 th latency) for receive-intensive network applications. |
|
|